Building a production-grade Retrieval-Augmented Generation (RAG) system is not just about connecting a vector database to an LLM. It's about carefully engineering every stage of the pipeline to ensure accuracy, relevance, and trustworthiness at scale.
Over the past few weeks, I've been deep in the process of designing, testing, and refining an end-to-end RAG pipeline. This post outlines the architecture, key design decisions, and areas of ongoing exploration.
System Overview
At a high level, the system is designed to:
- Retrieve the most relevant information from a knowledge base
- Construct a high-quality context for the model
- Generate accurate, grounded responses
- Provide transparency through source attribution and confidence scoring
The focus throughout has been clear: Give the LLM the right information, not just more information.
What's Implemented
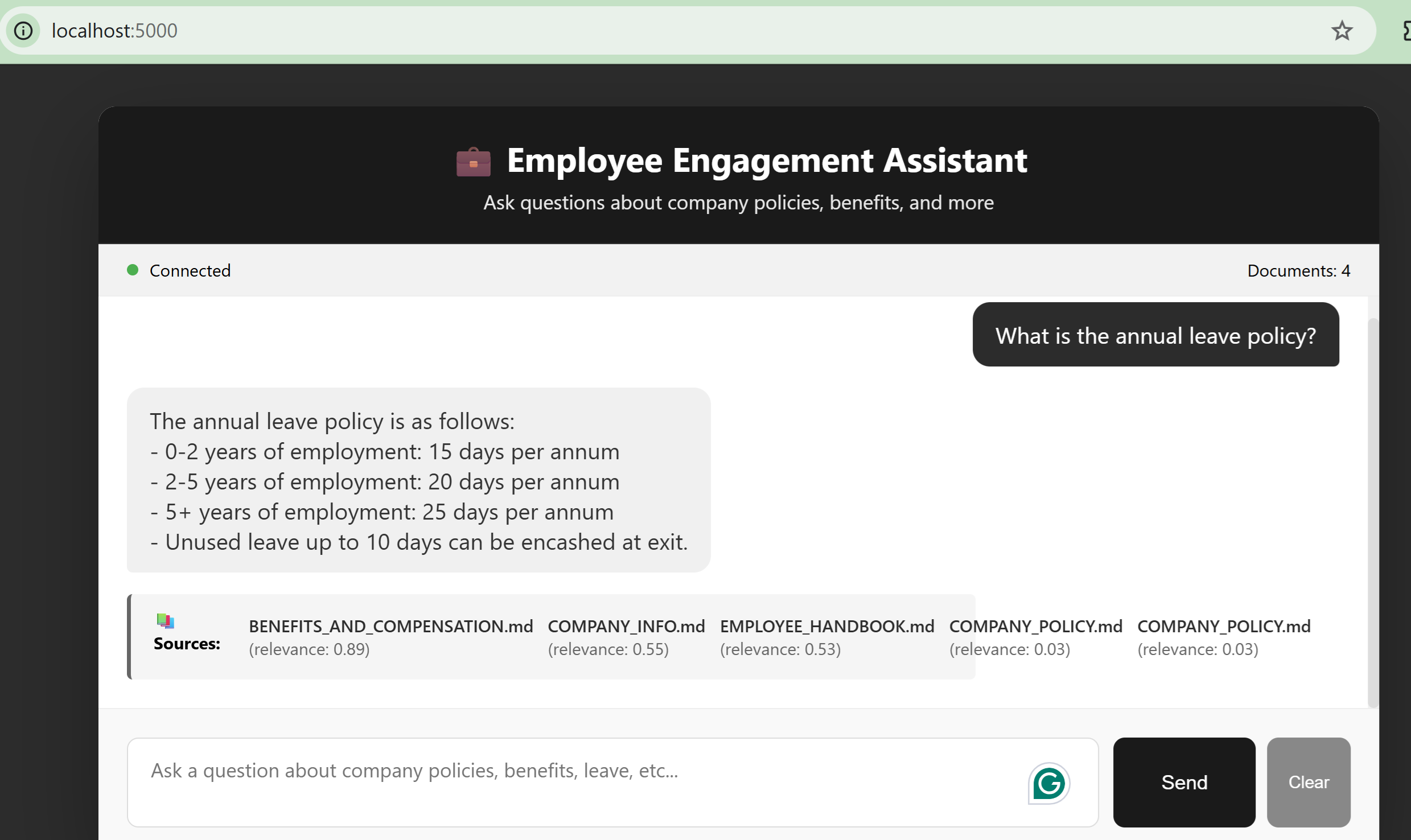
1. Hybrid Retrieval: Precision Meets Semantics
Instead of relying on a single retrieval method, the system combines BM25 (keyword-based search) for exact term matching with Vector embeddings for semantic similarity. This hybrid approach ensures both lexical precision and contextual understanding, significantly improving recall across diverse query types.
2. Reciprocal Rank Fusion (RRF)
To merge results from multiple retrieval strategies, RRF combines rankings in a way that consistently surfaces the most relevant documents across methods, rather than depending on raw scores which are often not directly comparable.
3. Cross-Encoder Reranking
After initial retrieval, results are passed through a cross-encoder reranker for stronger semantic relevance and better ordering of top results. This step significantly improves answer quality for nuanced or ambiguous queries.
4. Token-Aware Context Construction
Context is constructed with token limits in mind, giving priority to high-relevance chunks and filtering out redundant or low-value content, ensuring optimal utilization of the model's context window.
5. LLM-Based Answer Generation
Carefully designed prompts ground the model strictly in retrieved context, reduce hallucinations, and encourage structured, explainable responses.
6. Fallback Handling
For low-confidence scenarios, the system avoids overconfident or misleading answers and falls back to safer responses. This is critical for building trust in real-world applications.
7. Source Attribution & Confidence Scoring
Each response includes references to source documents and a confidence score based on retrieval and reranking signals, adding transparency and allowing users to verify outputs.
Key Focus Area: Retrieval & Context Engineering
The quality of a RAG system is largely determined before the LLM is even called.
Improving retrieval precision and context construction has a far greater impact than tweaking prompts alone.
What's Next
Smarter Chunk Selection
- Dynamic chunking strategies
- Query-aware chunk selection
- Reducing noise while preserving context completeness
Summarization vs. Truncation
Finding the right trade-off between summarization (more coverage, risk of information loss) and truncation (exact data, limited context) is key for maximizing signal within token limits.
Human-in-the-Loop Feedback
- Improve retrieval over time
- Adapt to real-world query patterns
- Continuously refine ranking and response quality
Final Thoughts
Building a production-ready RAG system is an iterative process that requires careful attention to retrieval, ranking, and context design, not just model selection.
As this system evolves, the goal remains the same: Deliver answers that are not only fluent, but factual, grounded, and trustworthy.