Distributed Rate Limiting: Lessons from Production
When a correct rate limiter becomes an incorrect architecture, and how shared state, Redis, and layered edge protection solve the hardest distributed systems problems.
May 29, 2026 12 min read Spring Cloud Gateway · Redis · Microservices
We design and implement production-grade API gateway architectures with distributed rate limiting, observability, and resilience built in from the start.
Rate limiting is only one component of a layered traffic protection strategy. Our request path is designed so each layer has a distinct, non-overlapping responsibility.
Most engineering teams encounter rate limiting early in their API journey. The implementation often starts with a familiar pattern:
private final ConcurrentHashMap<String, TokenBucket> buckets =
new ConcurrentHashMap<>();
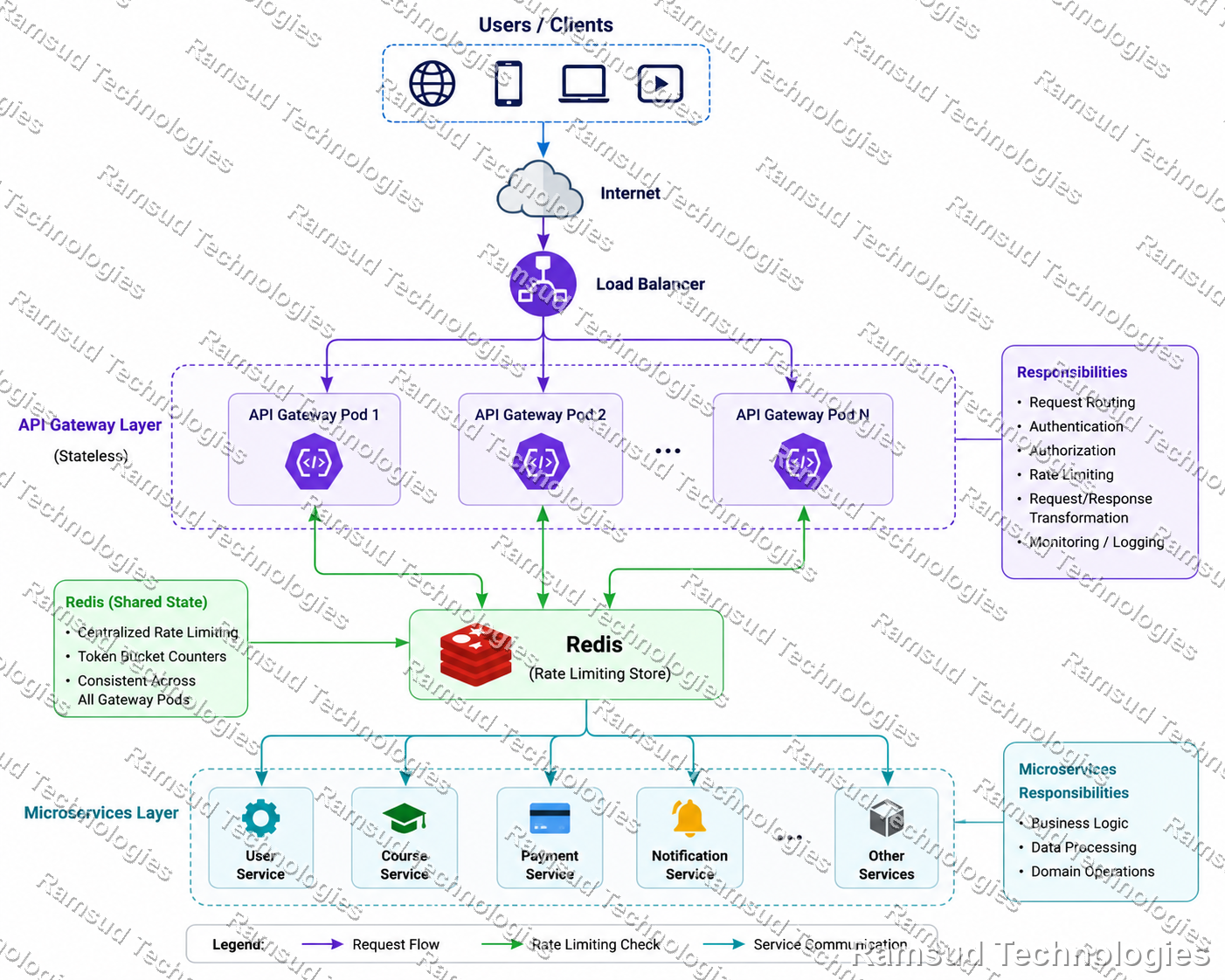
For a single application instance, this solution is simple, fast, and effective. The problem appears when the platform evolves, load balancers, autoscaling, Kubernetes, multiple availability zones, and eventually multiple gateway replicas. At that point, the challenge is no longer implementing a token bucket algorithm. The challenge becomes maintaining a consistent view of rate limits across a distributed system.
The Full Request Path
Fig 1, Distributed rate limiting with Redis shared state across all API Gateway pods
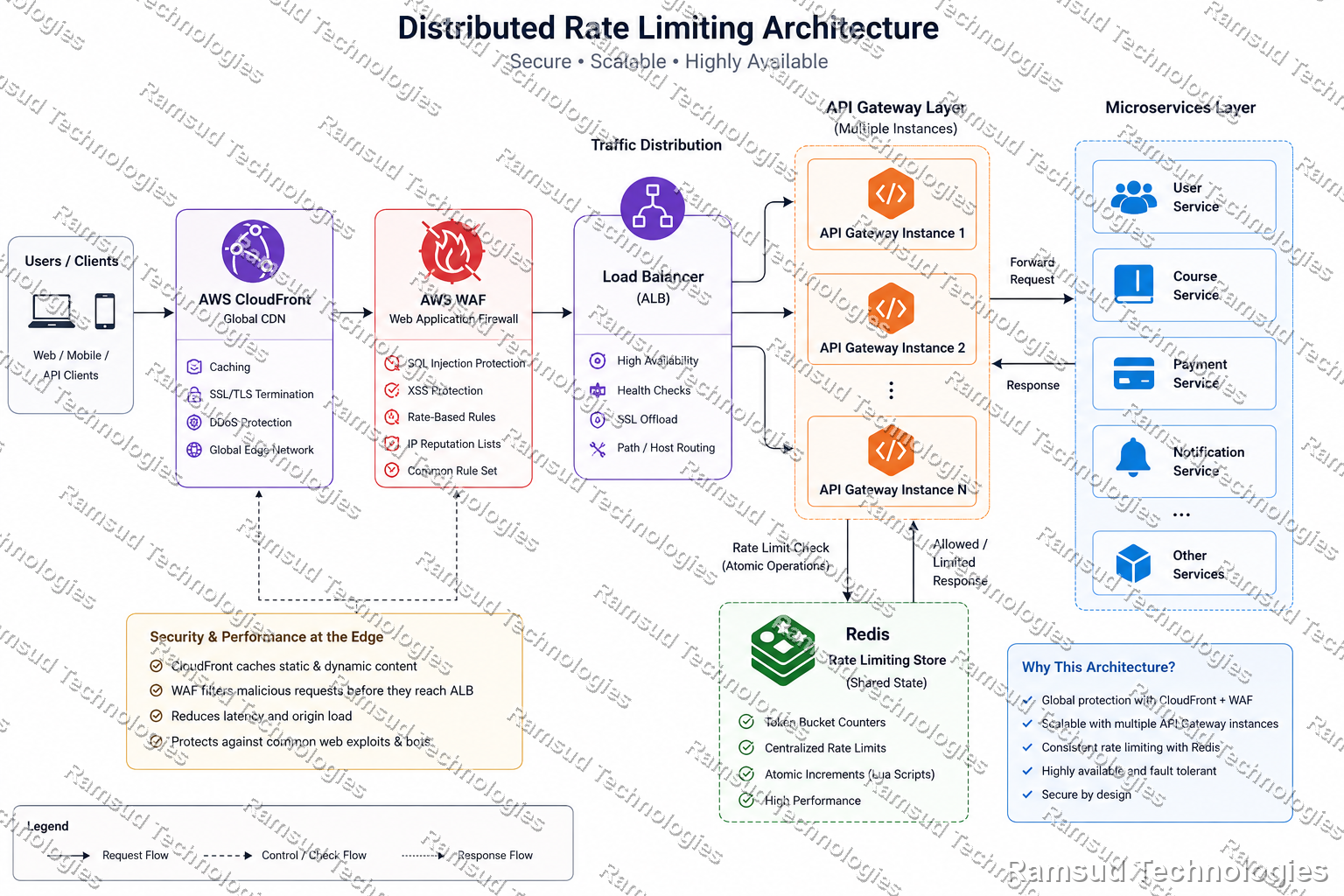
AWS CloudFront
CloudFront provides global edge caching, reduced latency, reduced origin load, and additional DDoS protection. Traffic is filtered and optimized before it reaches our infrastructure.
AWS WAF
AWS WAF protects against SQL injection attempts, cross-site scripting attacks, malicious bots, IP reputation threats, and excessive request rates. The goal is to stop unwanted traffic as close to the edge as possible.
Spring Cloud Gateway
Spring Cloud Gateway is responsible for authentication, authorization, request routing, request transformation, rate limiting, and observability. This is where application-level throttling occurs.
Design Principle: Stop unwanted traffic as early as possible in the request path, before it reaches compute resources that do real work.
Section 02
Why In-Memory Rate Limiting Breaks at Scale
A rate limiter that is functionally correct can still be architecturally wrong once you add a load balancer.
Consider a limit of 100 requests per minute. A single gateway instance enforces this correctly.
Client
|
Gateway
However, production environments rarely stay this simple. A more realistic deployment looks like:
+--> Gateway Pod 1
Load Balancer ----+--> Gateway Pod 2
+--> Gateway Pod 3
Each gateway pod maintains its own memory. This means:
Gateway Pod 1 = 100 requests
Gateway Pod 2 = 100 requests
Gateway Pod 3 = 100 requests
A client can effectively consume 300 requests per minute without violating any local limit.
"The token bucket implementation is functioning correctly. The architecture is not. Every gateway has a different view of reality."
The Hidden Risk: Autoscaling makes this problem dynamic. As traffic grows and new pods spin up, effective rate limits silently multiply, just when you most need them to hold.
Section 03
A Common Misconception About Resilience4j
A great library, but designed for a different problem domain entirely.
One misconception we frequently encounter is: "Why not use Resilience4j RateLimiter?"
Resilience4j is an excellent library and remains an important part of modern Java architectures. However, its primary purpose is different. Typical use cases include protecting downstream APIs, limiting outbound requests, preventing resource exhaustion, and implementing retries and circuit breakers.
This works extremely well when protecting external dependencies. However, each application instance maintains its own limiter state:
Gateway Pod 1 -> Limiter A
Gateway Pod 2 -> Limiter B
Gateway Pod 3 -> Limiter C
There is no distributed coordination. This is not a limitation of Resilience4j, it is simply outside the problem domain it was designed to solve.
Key Distinction
Resilience4j RateLimiter, protects outbound calls to external services. Per-instance, no coordination needed.
Distributed RateLimiter, enforces global inbound limits across all gateway replicas. Requires shared state.
Section 04
Why Shared State Becomes Necessary
To enforce a global limit, every gateway instance must evaluate requests against the same source of truth.
Conceptually, the transition looks like this:
Gateway Pod 1
Gateway Pod 2 ---> Shared State
Gateway Pod 3
Without shared state:
Limits become inconsistent across pods
Autoscaling silently changes enforcement behavior
Gateway replicas make independent decisions on the same client
"A distributed system requires a distributed view of consumption. There is no shortcut around this constraint."
Architectural Insight: Once you accept that shared state is required, the design question shifts from "how do we build a rate limiter?" to "how do we build a reliable distributed counter?"
Section 05
Why We Chose Redis
After evaluating multiple options, Redis provided the best balance between performance, simplicity, and operational maturity.
Requirement
Redis Capability
Shared state
All gateway replicas consult the same counters
Atomic operations
Rate-limit decisions remain consistent under high concurrency
Low latency
Sub-millisecond evaluation, no noticeable request overhead
Ecosystem maturity
Well-established pattern used across API gateways and service meshes
Spring integration
Native RedisRateLimiter in Spring Cloud Gateway
Why Atomic Matters: Rate limiting under high concurrency requires atomicity. Without it, two pods can both read "99 requests used" and both approve request 100, breaking the limit. Redis Lua scripts execute atomically, eliminating this race condition.
Section 06
Leveraging Spring Cloud Gateway's Native Capabilities
Avoiding a custom distributed rate-limiting implementation was an important architectural decision.
Spring Cloud Gateway already provides:
RequestRateLimiter
RedisRateLimiter
This allowed us to use a proven implementation instead of building and maintaining our own distributed coordination mechanism. The RedisRateLimiter uses a token bucket algorithm implemented as an atomic Lua script, handling concurrency correctly without custom code.
"Whenever possible, platform capabilities should be preferred over custom infrastructure code. The maintenance burden of a homegrown distributed rate limiter is significant."
Practical Benefit: Spring Cloud Gateway's RedisRateLimiter is battle-tested across thousands of production deployments. Building an equivalent from scratch requires solving distributed counter atomicity, clock skew, TTL management, and connection pooling, problems already solved in the platform.
Section 07
Rate Limiting Is Not One Rule
Different consumers require different controls. Production rate limiting should be layered by consumer type and endpoint sensitivity.
Anonymous Requests
Limited primarily by IP address. Useful for blocking bots, crawlers, and brute-force attempts before they consume authenticated resources.
Authenticated Requests
Limited by User ID, Tenant ID, or API Key. Supports fair usage policies, multi-tenant isolation, and per-customer abuse prevention.
Sensitive Endpoints
Additional restrictions applied to high-risk paths:
/login
/register
/password-reset
/token
These endpoints have fundamentally different security requirements than standard business APIs. A credential-stuffing attack may only send 10 requests/minute per IP, well within typical API limits, but still cause enormous damage if those limits aren't tightened at the endpoint level.
Common Mistake: Applying a single global rate limit across all endpoints. Sensitive endpoints like /login require aggressive limits (e.g., 5 req/min) while bulk data APIs may legitimately need thousands.
Section 08
Designing for Failure
One of the most important architectural discussions: what happens if Redis becomes unavailable?
Many distributed rate-limiting designs effectively turn Redis into a critical dependency. If Redis is down, requests are either denied entirely (fail-closed) or allowed entirely (fail-open). For customer-facing platforms, either extreme can create an unnecessary outage or security gap.
We deliberately chose a different approach, a degraded operating mode with local fallback.
The Core Question: Is it more acceptable to briefly enforce inconsistent rate limits, or to briefly make your entire platform unavailable while Redis recovers?
Section 09
Choosing Availability Over Perfect Consistency
A conscious tradeoff between global consistency and platform availability during Redis outages.
Normal Operation
Gateway Pods
|
v
RedisRateLimiter (global shared state)
Redis Unavailable
Gateway Pods
|
v
Local Token Buckets (per-pod fallback)
In degraded mode, requests continue flowing and local throttling remains active. What we lose is global consistency, each gateway replica temporarily enforces limits independently.
"For our platform, preserving customer availability was more important than maintaining perfectly synchronized rate limits during a Redis outage. That is a conscious tradeoff, not an oversight."
When Fail-Closed Is Right: For high-security APIs (banking, healthcare, authentication services), fail-closed (deny all when Redis is down) may be the correct choice. The right answer depends on your platform's risk profile, not a universal best practice.
Section 10
Observability Is Part of the Design
Fallback strategies are only valuable if teams know they are active.
We expose metrics through Prometheus and visualize them in Grafana. Key indicators include:
rate_limiter_allowed_total
rate_limiter_denied_total
rate_limiter_redis_errors_total
rate_limiter_fallback_activations_total
rate_limiter_degraded_mode_active
rate_limiter_latency_ms
This gives operators immediate visibility into Redis connectivity issues, increased traffic volume, abuse patterns, and gateway behavior changes.
Alert on Degraded Mode:rate_limiter_degraded_mode_active should trigger a PagerDuty alert. Degraded mode is not a silent fallback, it means Redis is unavailable and the team needs to act.
"Observability is not an afterthought. It is a core architectural requirement. A fallback that activates silently is a liability, not an asset."
Section 11
Defense in Depth
Even during a Redis outage, multiple protection layers remain active.
Fig 2, Defense in depth: every layer provides independent protection
This layered approach ensures that no single component becomes the sole line of defense. Rate limiting works best when combined with edge protection, security controls, and application-level safeguards.
Why Layers Matter: No single layer is perfect. CloudFront can be bypassed via direct IP access. WAF rules have false positives. Redis can fail. The combination of layers makes catastrophic failure extremely unlikely.
Section 12
Final Thoughts
Distributed rate limiting is not primarily a rate-limiter problem, it is a distributed systems problem.
The challenge is not implementing token buckets, counters, or throttling rules. The challenge is ensuring that multiple gateway instances make consistent decisions while preserving availability when dependencies fail.
Layer
Role in Our Architecture
Spring Cloud Gateway
Enforcement layer, routing, auth, rate limiting
Redis
Shared distributed state for consistent limits
CloudFront + AWS WAF
Edge protection, DDoS, bot filtering, IP reputation
Local token buckets
Degraded-mode resilience when Redis is unavailable
Prometheus + Grafana
Operational visibility across all layers
"In distributed systems, the most important architectural decisions are often not about algorithms. They are about tradeoffs, balancing consistency with availability while keeping operational complexity manageable."
Key Takeaways
In-memory rate limiting breaks the moment a load balancer is introduced.
Resilience4j is for outbound protection, not inbound distributed rate limiting.
Redis shared state is the standard solution; Spring Cloud Gateway's RedisRateLimiter implements it correctly.
Rate limiting must be layered by consumer type and endpoint sensitivity.
Design fallback behavior intentionally, the right choice depends on your platform's risk profile.
Observability is not optional. Degrade visibly, alert, and recover.